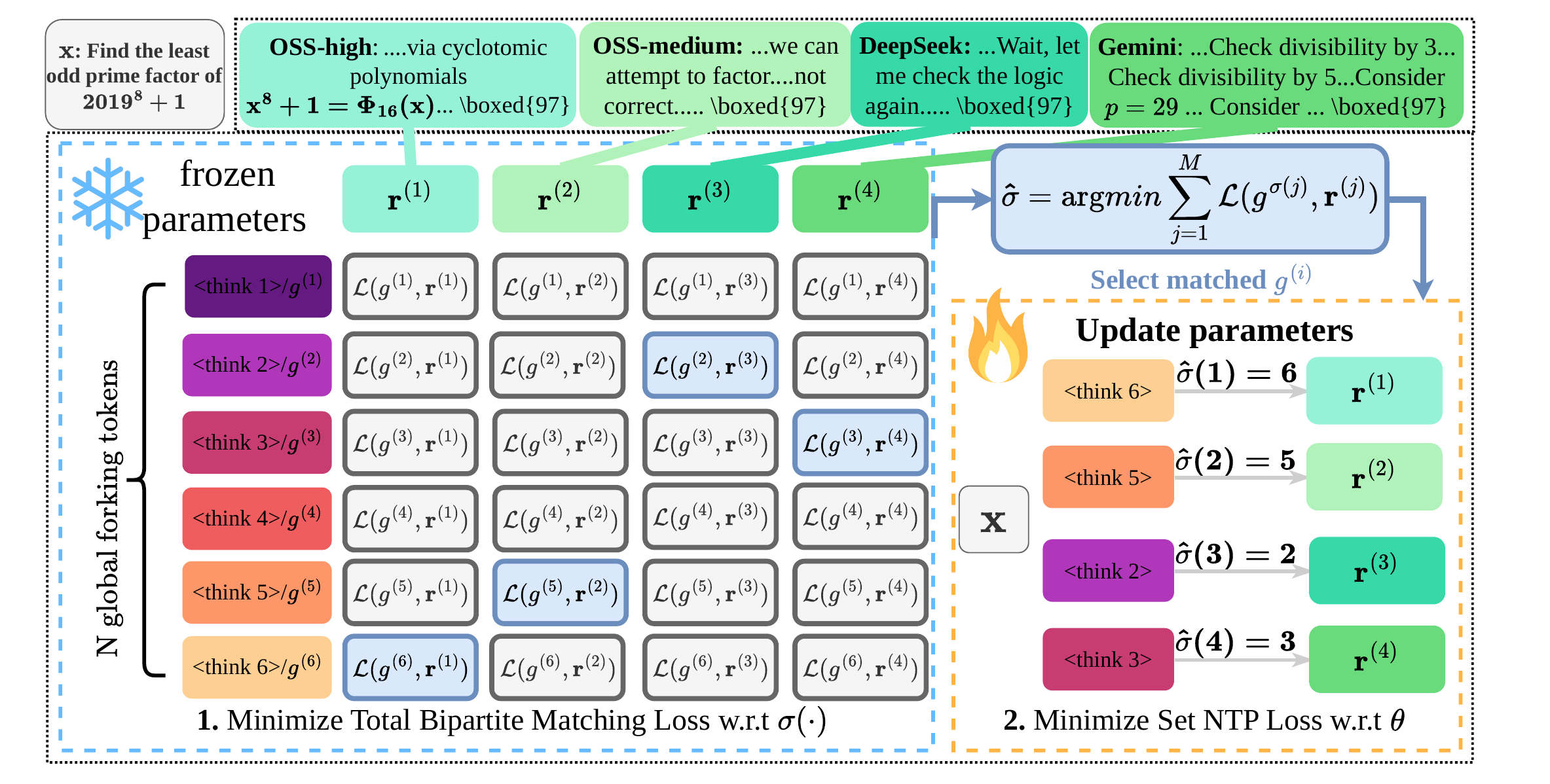
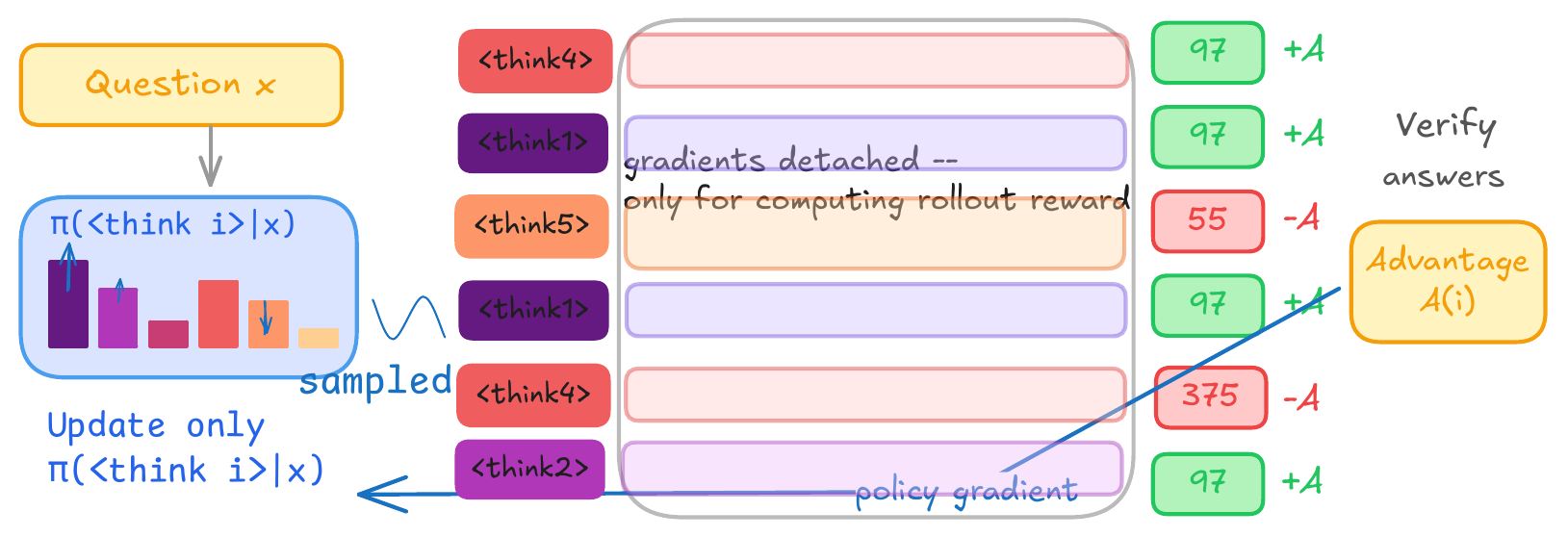

Motivation for Principled SFT for Parallel Reasoning
Why care about parallel reasoning?
- It reveals reasoning capability boundaries, via metrics such as pass@k.
- Test-time compute such as self-consistency relies on it.
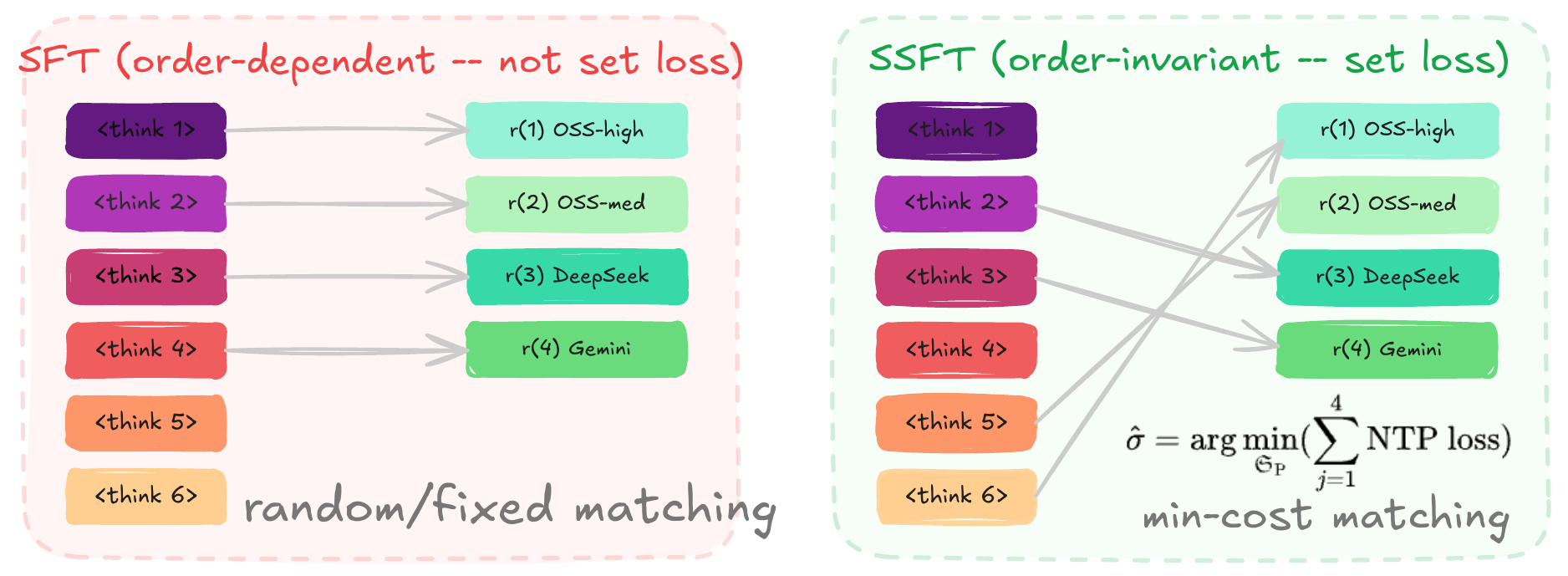
Goal. Since reasoning capacity of RLVR models is shown to be bounded by the base model (Yue et al., 2025), we aim to expand it through SFT. SFT with diverse traces aligns with how reasoning capacity is measured via parallel generations at inference.

Limitations of SFT models naively trained with diverse traces.
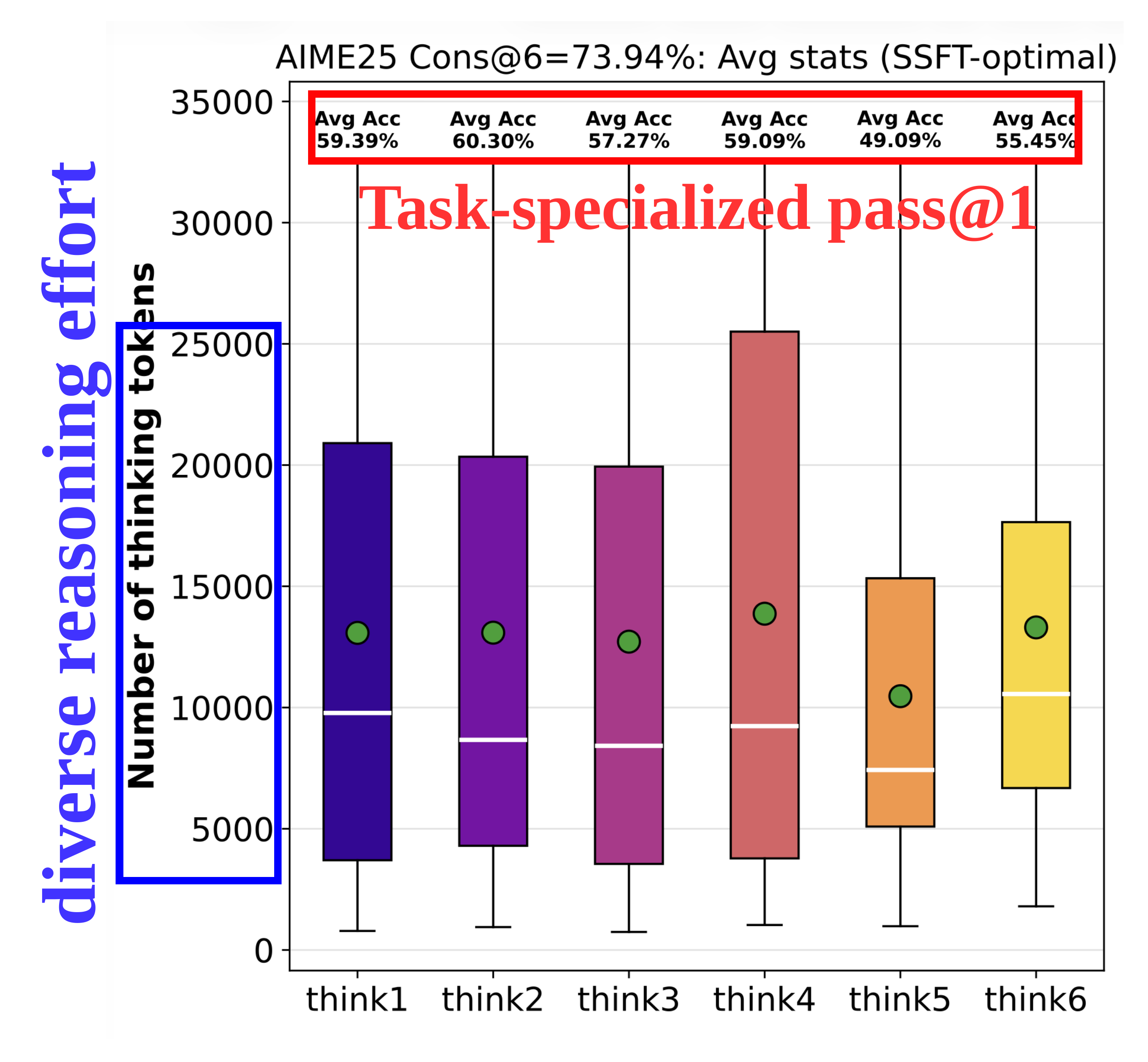
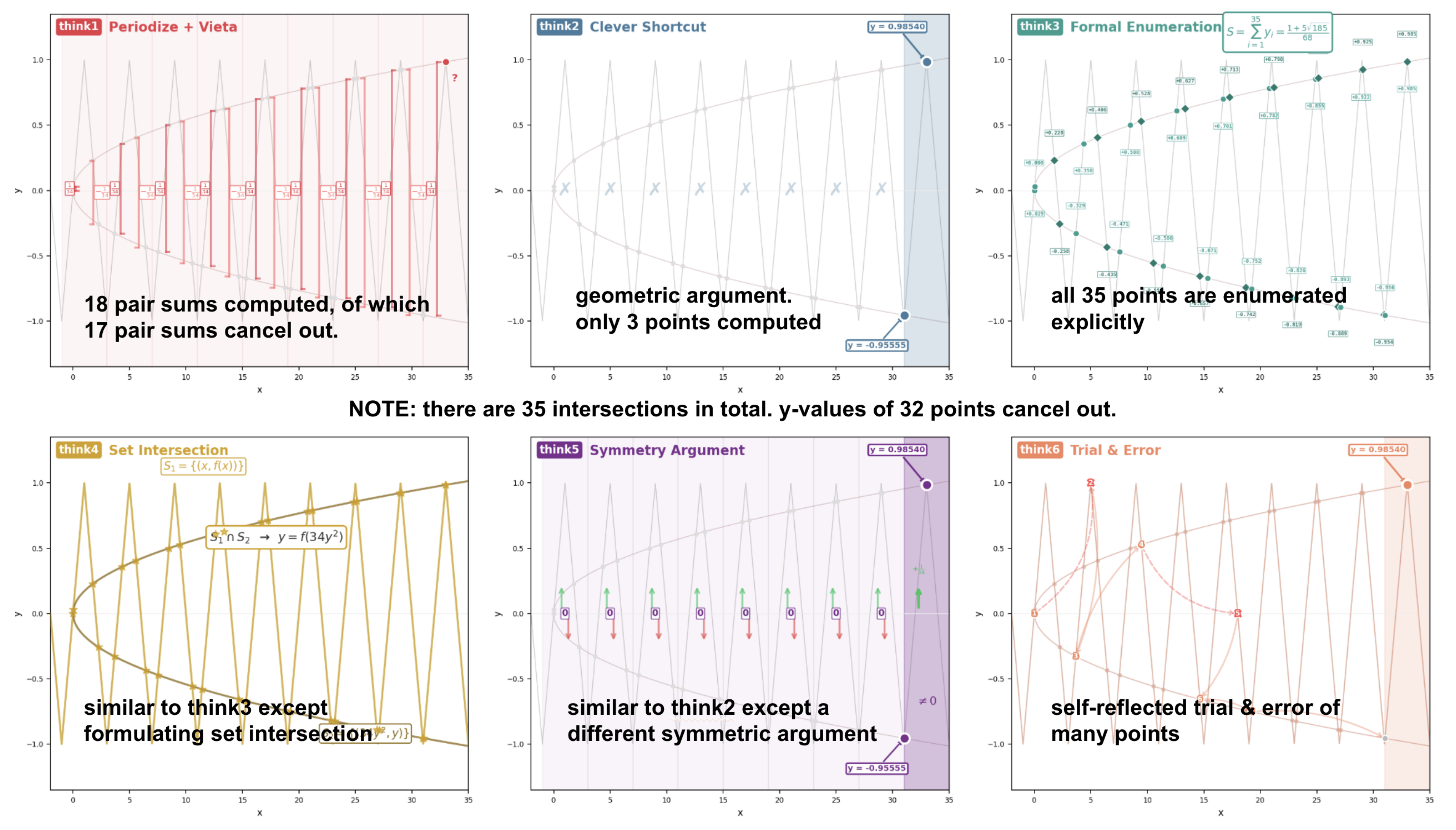
Mode collapse — Parallel generations do not genuinely elicit distinct reasoning.
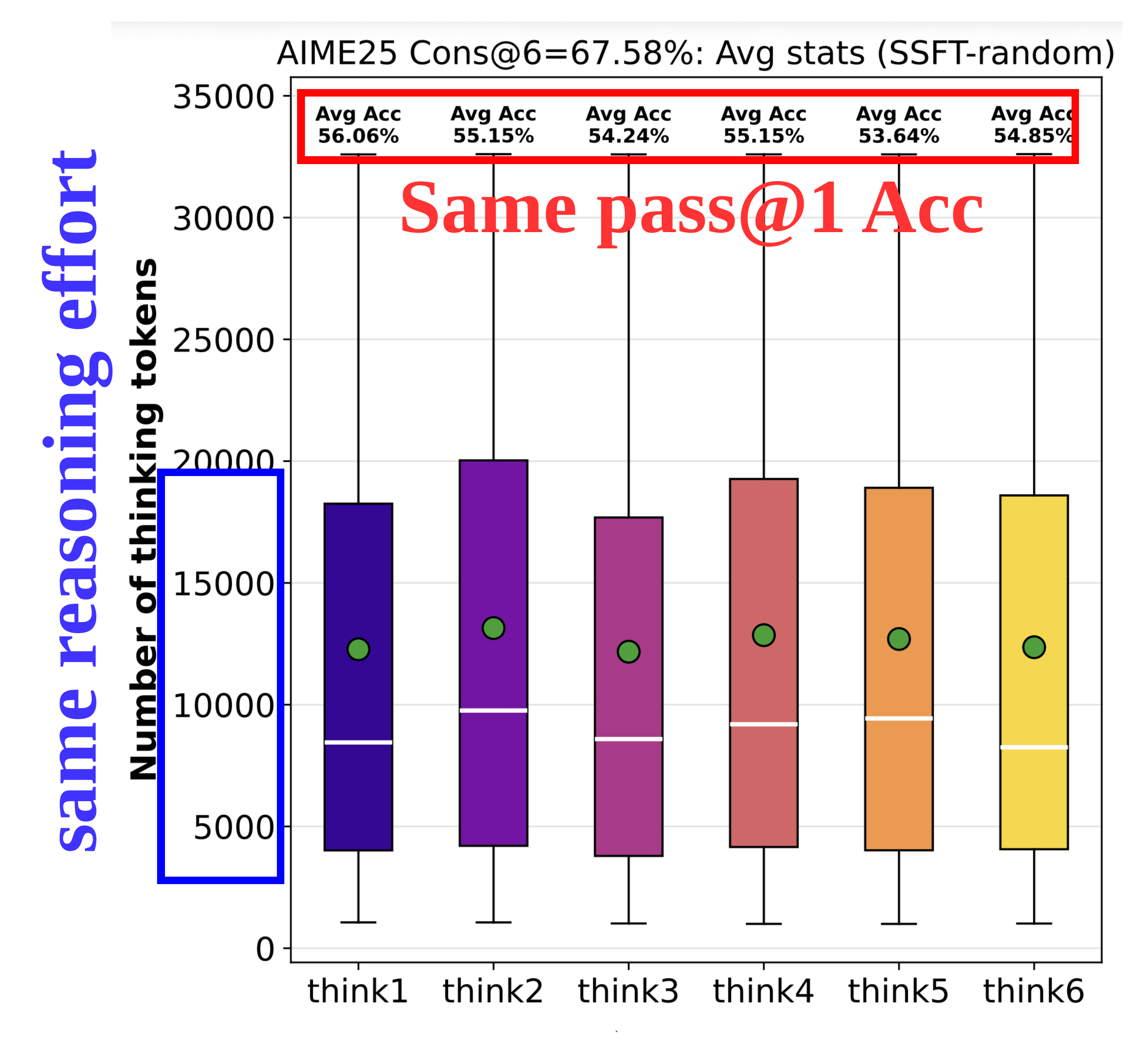
(a) Mode collapse of parallel generations under metrics such as reasoning effort and accuracy.
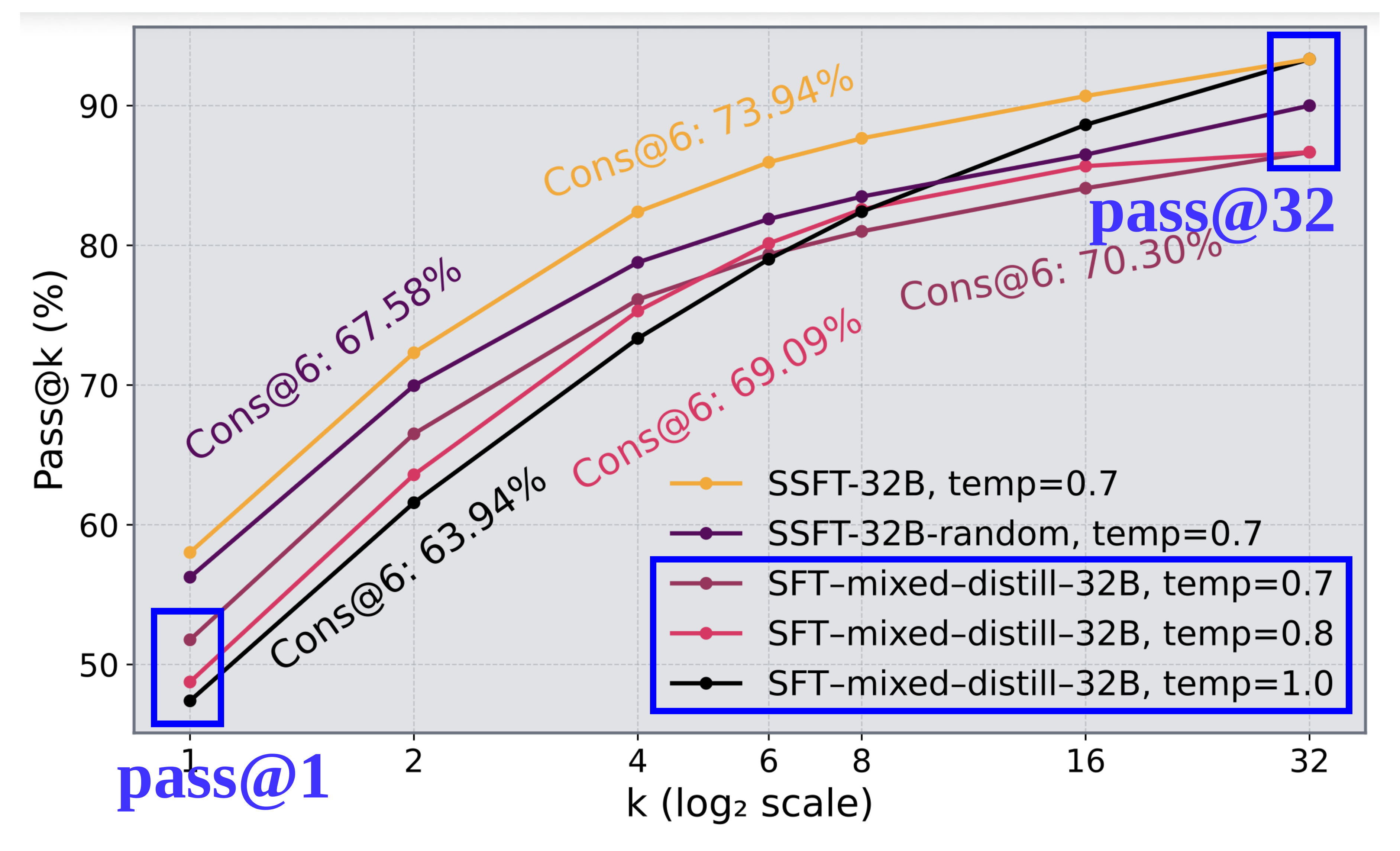
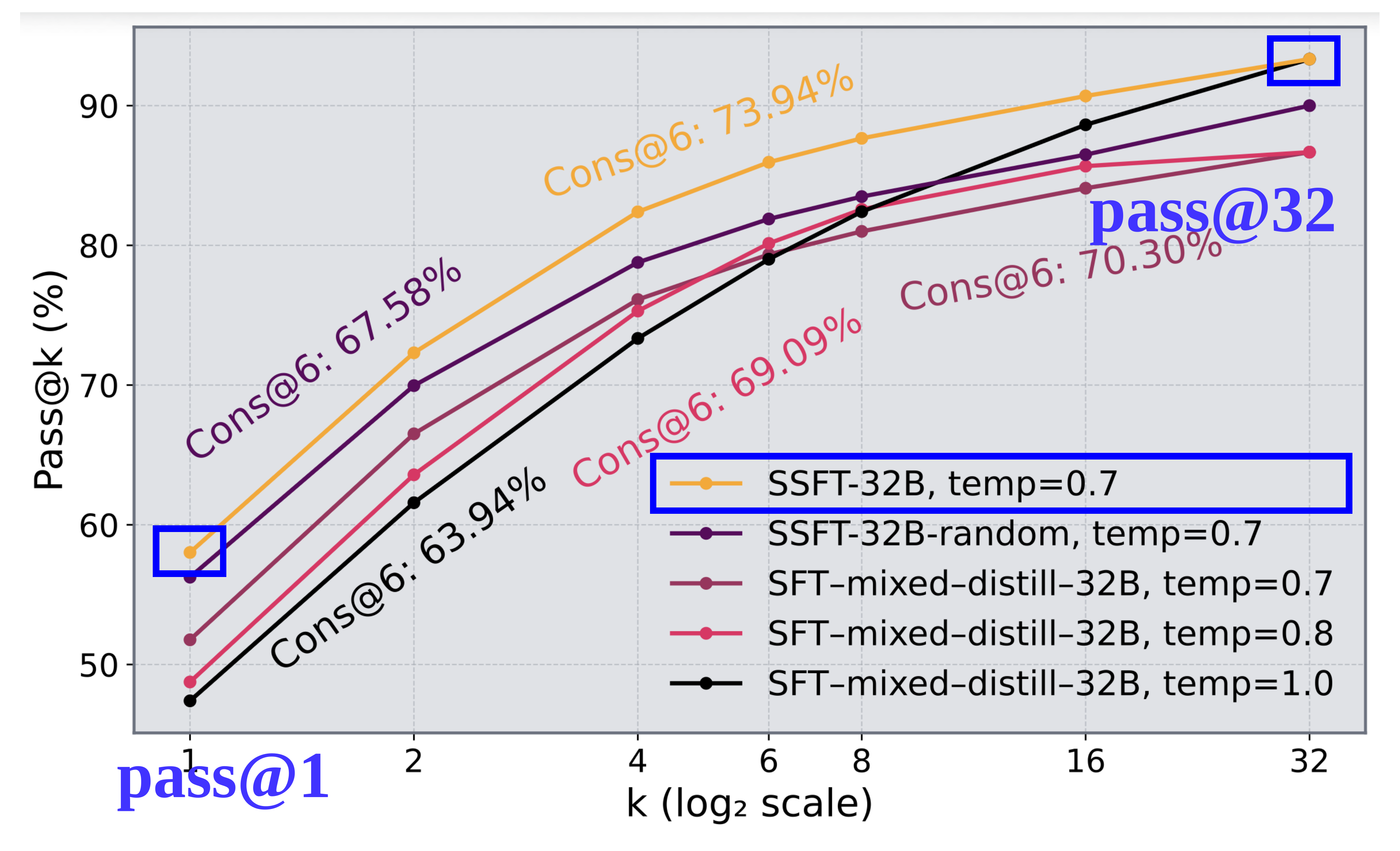
(b) Recurring diversity (pass@k) vs accuracy (pass@1) trade-off under temperature scaling for steerability during inference (AIME25).